Xiaomi MiMo is officially launched by the company which is the AI Model (Open Sourced). It is the powerful next gen MoE AI Model which matches the DeepSeek on General Watermarks and more. In this article you will see dedicated details regarding the Xiaomi MiMo. Check below to see the latest details now.
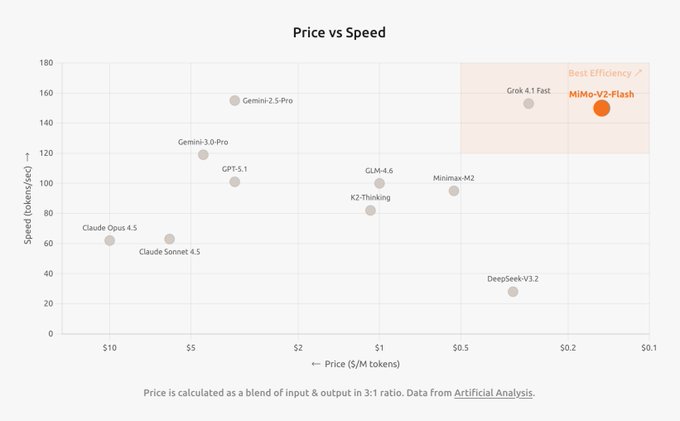
MiMo V2 Flash – Super Fast
- Hybrid Attention: 5:1 interleaved 128-window SWA + Global attention with 256K context
- Benchmark Performance: Matches DeepSeek-V3.2 on general benchmarks at much lower latency
- SWE-Bench Results: SWE-Bench Verified: 73.4% and SWE-Bench Multilingual: 71.7%
- New open-source SOTA
- Speed: Up to 150 output tokens/sec with Day-0 support
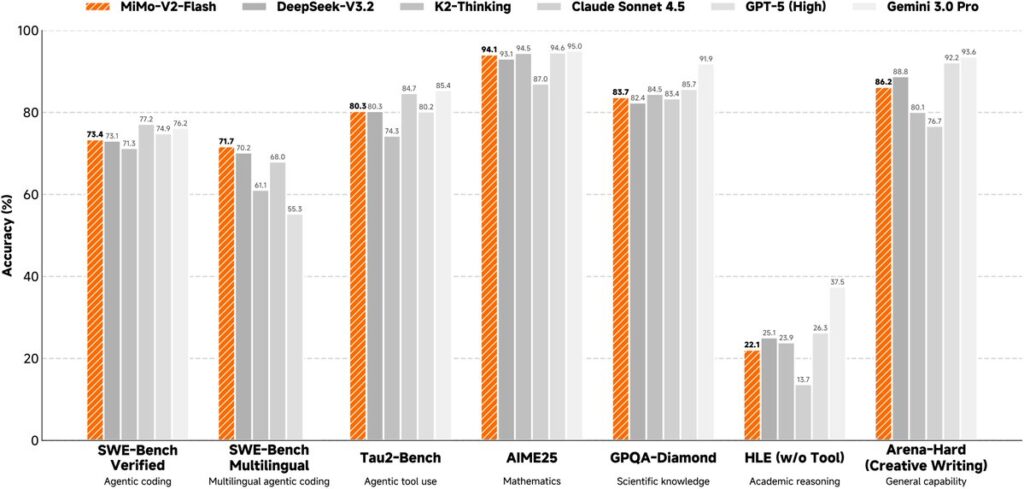
MiMo Architecture
Architecture Overview
- Hybrid attention: Sliding Window + Global in a 5:1 ratio
- 8 hybrid blocks: 5 SWA layers → 1 Global layer
- 128-token sliding window
- 256 experts, 8 active per token
- Trained natively at 32K context, extended to 256K
Key Findings
- Attention sink bias is critical
- Without it: SWA performance drops sharply
- With it: SWA matches or beats full global attention
- Smaller windows perform better
- 128 vs 512: similar on short benchmarks
- After 256K extension: 128-token SWA leads, 512-token SWA collapses
MTP: Faster Training & Inference
- 3 lightweight heads (0.33B each)
- Act as draft models for speculative decoding
- 2.5× faster decoding speed
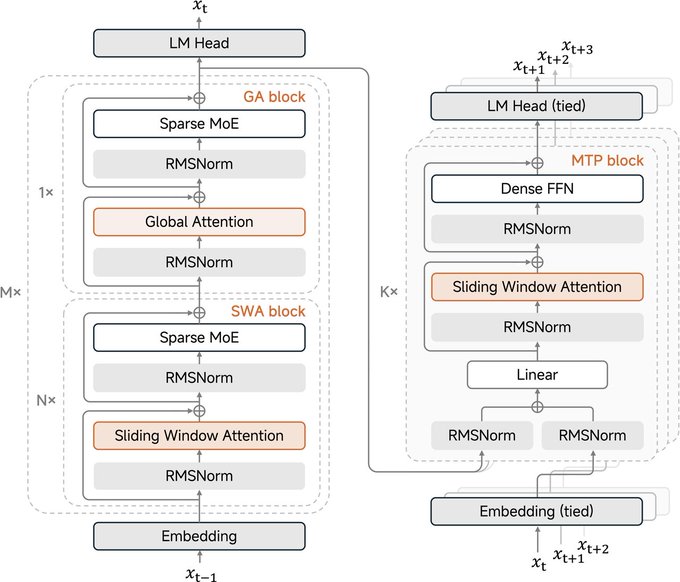
MiMo – MOPD
Multi-Teacher On-Policy Distillation (MOPD)
Problem
- Post-training “see-saw” effect
- Improving math breaks coding
- Enhancing reasoning hurts safety
Solution
- Train specialized expert teachers
- Distill all teachers into one student
- Use on-policy RL with token-level KL rewards
Results
- 1/50th compute vs training specialists
- Matches each teacher in its own domain
- No capability trade-offs
- Iterative loop: today’s student → tomorrow’s teacher
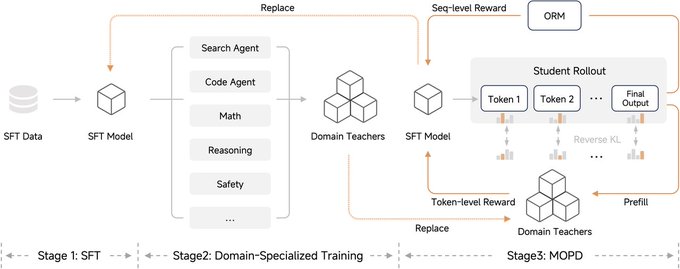
MiMo – MTP
Faster LLM Decoding
- LLM decoding is memory-bound; low arithmetic intensity limits throughput
- Batch parallelism helps FFN, but not attention (separate KV cache per request)
- MTP approach: draft tokens generated first → main model verifies in parallel
- Enables token-level parallelism without extra KV cache I/O
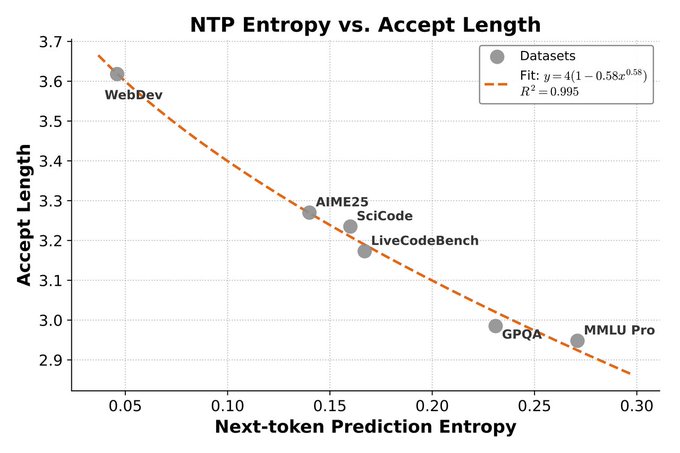
- With 3-layer MTP: 2.8–3.6 accepted tokens per step and 2.0–2.6× real decoding speedup
Accelerating RL Training
- Rollout is the biggest RL bottleneck
- MTP scales token-level parallelism instead of batch size
- Enables stable, efficient on-policy RL with small batches
- Removes GPU idle time from long-tail stragglers when batch size ≈ 1
- Result: faster, more stable, more efficient RL
Price
For Now MiMo is free for everyone but its for limited time, after that Xiaomi MiMo will become paid, so for now you have chance to use it so check below the Website and use it now.